

Each page's script is detected first.
Every page is independently classified — printed vs handwritten; Hindi, English, or mixed — which tunes how the engine reads it. Real Indian case files, handled.
Pillar 04 · Legal document digitization for India
LawVriksh turns scanned and handwritten case files into verified, usable case knowledge — not just searchable PDFs.
Real digitization means the text is read, the critical legal values are pulled out, checked by a human — and only then allowed into the case. Nothing enters the case memory until it's verified.
The question this answers
"What does real digitization of my files actually mean?"
Read, verified, and only then — usable knowledge.
What it means
That's not digitization — it's a photo. Real digitization means the text is read, the legally critical values (FIR number, sections, party names, dates) are pulled out correctly, checked by a human, and only then allowed into the case knowledge.
The file is there — but the knowledge inside it is locked and unverified.
Years of FIRs, chargesheets and orders sit as scans nobody can search. Witness statements and affidavits are handwritten, in Hindi, English, or mixed script — the hardest content to read reliably.
And there is a real danger: if OCR misreads an FIR number or a section and that wrong value flows into answers and drafts, you get confidently wrong output — worse than no answer. So nothing enters until it's checked.
"A scanned PDF is not a digitized matter. Digitization means your file becomes verified, usable case knowledge — readable, searchable, and trustworthy."
The real problem
Years of FIRs, chargesheets and orders sit as scans nobody can search.
Witness statements and affidavits are handwritten — in Hindi, English, or mixed script — the hardest content to read reliably.
A reopened matter has annexures that are just images; finding one fact means flipping through pages by hand.
If OCR misreads an FIR number or a section and it flows into answers and drafts, you get confidently wrong output — worse than no answer.
The common thread: the file is there, but the knowledge inside it is locked and unverified. Digitization is the act of safely unlocking it.
How it works
Digitize, then understand — but nothing reaches the knowledge base until a human has approved it.
To the matter or the Personal Database vault — including scanned and handwritten pages.
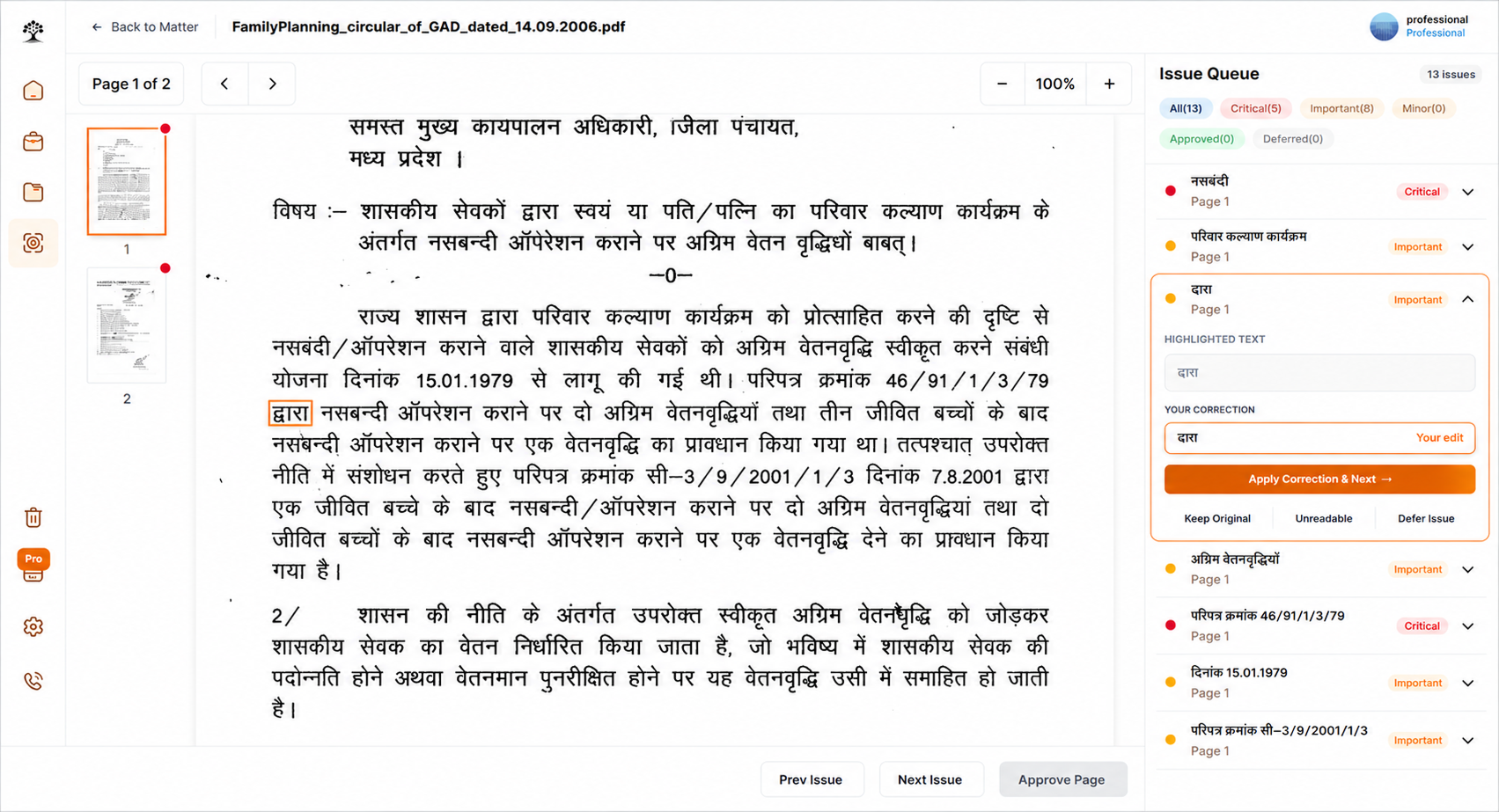
Each page is classified by script — printed or handwritten; Hindi, English, or mixed — and read accordingly.
A misread FIR number, a fuzzy date — surfaced on the review screen and ranked by severity.
Correct the flagged values and approve the document. Critical issues must be resolved first.
Verified text becomes available for Q&A, facts, timeline and drafting. Nothing else gets through.
There is no claim of 100% accurate OCR. The system knows what it's unsure about — and refuses to let unverified values through. Verified, not flawless.
Behind the scenes
Each capability below is a mechanism — the reason a claim about real digitization is actually true.
Every page is independently classified — printed vs handwritten; Hindi, English, or mixed — which tunes how the engine reads it. Real Indian case files, handled.
Low-confidence values become issues, ranked Critical, Important, or Minor — so the system knows what it's unsure about instead of pretending everything is fine.
An FIR number or section is Critical even at high confidence, and severity can't be downgraded by hand — the highest-risk fields always get human eyes.
A document can't be marked reviewed while Critical issues are open. Nothing enters the knowledge base until it's verified — and only verified text feeds Q&A and drafting.
Files with zero issues are auto-approved; everything else is triaged in one Review Queue — humans only touch what needs it.
A correction is stored as a new extraction version; the original scan and original OCR are always preserved — an auditable trail.
Before you ask
Yes. Each page is classified by script — printed or handwritten, Hindi, English or mixed — and read accordingly. Handwritten and mixed-script pages are the hardest, so anything uncertain is flagged for you to confirm.
Those are legally critical fields, always treated as Critical. The document cannot be marked reviewed while a Critical issue is open — so a misread can't silently slip into your case knowledge.
No. Documents with no issues are auto-approved. You only review the values the system is unsure about, shown in one Review Queue.
No. The original scan and original OCR are preserved; your correction is saved as a new version. You always keep the source intact.
A scan is a picture. Here the text is read, the key legal values are extracted and verified, and only then does it become usable, searchable case knowledge. If a scan is very poor, the system flags it and can retry with a higher-tier engine.
Founding members
Join India's case intelligence workspace built on your own documents. 250 Founding Member spots.